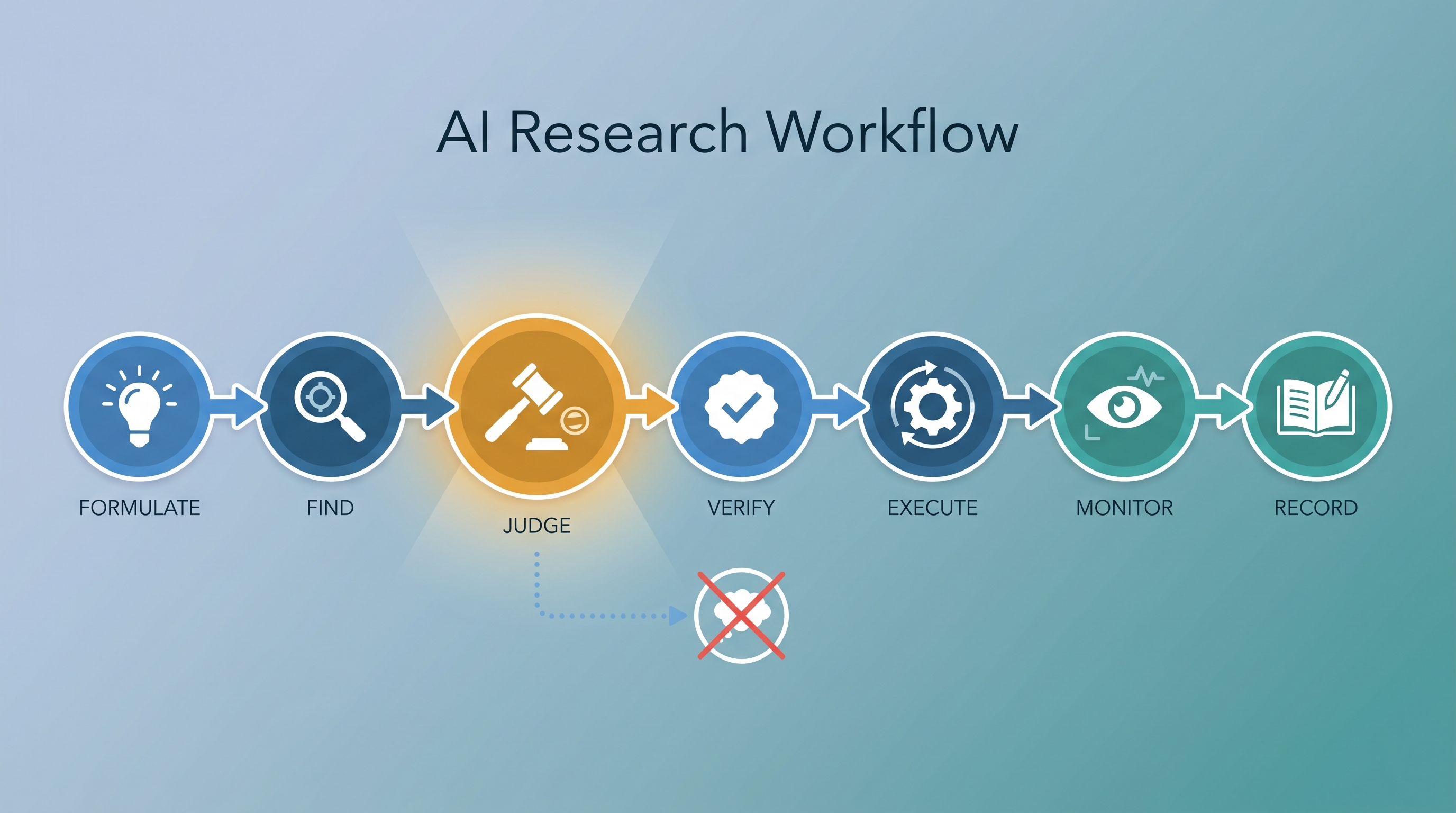
A 7-stage pipeline for AI-assisted academic research that uses Claude, Codex, Feynman skills, autoresearch, and scheduled agents — each at the right moment. Distilled from a real research session where the JUDGE stage (hostile peer review) caught a fundamentally wrong research direction in 4 minutes, saving weeks of wasted work.
| *Source: Karpathy AutoResearch | Feynman AI Research Agent | Down Sensitivity in DP* |
The Pipeline
FORMULATE → FIND → JUDGE → VERIFY → EXECUTE → MONITOR → RECORD
Most researchers go Find → Execute. The critical insight: never skip JUDGE. Running a hostile peer review before committing to a direction is the single highest-ROI step in the entire workflow.
| Stage | Purpose | Tool | Time |
|---|---|---|---|
| FORMULATE | Crisp hypothesis + falsification criteria | Thinking | 15 min |
| FIND | Survey landscape | /feynman:literature-review, /query-kb, WebFetch |
30-60 min |
| JUDGE | Kill bad ideas | /feynman:peer-review, /feynman:source-comparison |
15 min |
| VERIFY | Independent second opinion | Codex rescue + non-LLM check | 10 min |
| EXECUTE | Do the work | Autoresearch, direct coding | Variable |
| MONITOR | Track progress | Scheduled agents, /feynman:watch |
Ongoing |
| RECORD | Prevent context drift | Research state file | 10 min/stage |
Stage 0: FORMULATE — Before Anything Else
Write four things before touching any tool:
- Hypothesis: One sentence. “We want to prove X” or “We want to build Y.”
- Success criteria: What does “done” look like?
- Falsification criteria: What would make you STOP or PIVOT?
- Cost of being wrong: Hours? Days? Weeks?
The cost estimate gates how thorough later stages need to be. A 2-week wrong direction demands heavy JUDGE + VERIFY. A 2-hour experiment can skip straight to EXECUTE.
Rule: If you can’t write the hypothesis in one sentence, you’re not ready for Stage 1.
Stage 1: FIND — What’s Out There
Run 2-3 search agents in parallel to cover different angles:
Agent 1: /feynman:literature-review "topic keywords"
Agent 2: /feynman:deep-research "specific technical question"
Agent 3: WebFetch on known reference URLs
Always check your own knowledge base first (/query-kb) before searching externally. Don’t over-research — 30-60 minutes is enough to have a plan worth critiquing.
Stage 2: JUDGE — The Critical Step
This is where the workflow earns its keep. Run three review agents in parallel:
| Agent | Role | Prompt Pattern |
|---|---|---|
| Reviewer #2 | Hostile peer review | “Critique this plan. Find reasons to reject.” |
| Tool Comparison | Approach alternatives | “Compare approach A vs B vs C for this problem.” |
| Deep Dive | Feasibility of hardest part | “Is the hardest component actually achievable?” |
Rules:
- Mandatory if cost of wrong direction > 1 day
- Optional for small, reversible tasks
- The peer review agent must be HOSTILE — polite reviews don’t catch real problems
What JUDGE Catches
In our FormalDP project, Reviewer #2 said:
“You’re verifying things that are trivially true by hand. Histogram sensitivity = 1 is a one-sentence observation. You’re spending more effort convincing the solver than convincing a human.”
Cost of this critique: 4 minutes. Savings: potentially weeks of encoding work on the wrong targets. The project completely pivoted based on this feedback.
Stage 3: VERIFY — Independent Second Opinion
After revising based on JUDGE, get a second AI model to independently assess:
Codex rescue → "Review these three framings. Which do you endorse?"
Improved consensus rule: “If both agree, proceed” → “If both agree AND at least one non-LLM check passes, proceed.”
Non-LLM checks include: proof sketch, counterexample search, baseline run, cited primary source. Two AI models agreeing reduces bias but doesn’t eliminate correlated errors.
Stage 4: EXECUTE — Now Start Building
Autoresearch works when you have:
- Measurable output (sat/unsat, accuracy, test pass/fail)
- Modifiable input (code, encodings, configs)
- Clear objective (improve metric)
The loop: modify → measure → keep/discard. ~12 experiments/hour.
Critical rule: Autoresearch is an EXECUTION tool, not an IDEA tool. It optimizes within a direction — it doesn’t choose the direction. That’s FORMULATE + JUDGE.
Stage 5: MONITOR — Keep the Project Alive
| Scale | When | Setup |
|---|---|---|
| Light (default) | Most projects | 1 daily briefing agent |
| Medium | Active projects | + event-triggered workers |
| Heavy | Paper races, overnight experiments | 2-4 agents with different schedules |
Each agent must have a verification requirement — cross-reference findings, mark unverified claims. Don’t create monitoring overhead that exceeds the value of monitoring.
Stage 6: RECORD — Don’t Lose Context
Maintain a research state file updated at each JUDGE or VERIFY stage:
## Claims
| Claim | Evidence | Status |
|---|---|---|
| "X has sensitivity ≤ 2" | Proven (sat,47) | Verified |
| "POPL is feasible venue" | Codex rejected | Rejected |
## Rejected Alternatives
- Tried approach A, rejected because [reason]
## Next Falsification Step
- Run counterexample search on assumption Y
Distinguish “proven,” “observed,” and “guessed.” Record rejected alternatives — future-you will wonder why you didn’t try X.
Workflow Profiles
Theory-Heavy (proofs, formalizations)
FORMULATE → FIND → JUDGE(heavy) → VERIFY(heavy) → EXECUTE(light) → RECORD
Emphasize JUDGE. Key risk: weeks on a trivially true result. MONITOR is low cadence.
Empirical-Heavy (ML experiments, benchmarks)
FORMULATE → FIND → EXPLORE(bounded) → JUDGE → VERIFY → EXECUTE(heavy) → MONITOR(heavy)
Add early EXPLORE (bounded autoresearch for baselines). Key risk: evaluation leakage.
Engineering-Heavy (systems, tools)
FORMULATE → FIND(light) → JUDGE(light) → EXECUTE(heavy) → MONITOR(heavy) → RECORD
Compress FIND. Key risk: integration failures, not literature gaps.
Anti-Patterns
| Anti-Pattern | Why It Fails | Fix |
|---|---|---|
| Skip JUDGE, go to EXECUTE | Waste weeks on wrong target | Hostile review for high-cost decisions |
| “Both AIs agree = truth” | Correlated errors | Add non-LLM check |
| 4 agents for slow project | Alert fatigue | Scale monitoring to volatility |
| Autoresearch for ideation | Hill-climbing on bad metrics | Use for execution only |
| Never record rejections | Forget why you didn’t try X | Update state file each stage |
Case Study: FormalDP — How This Workflow Saved Weeks
This workflow was distilled from a real research session. Here is the full timeline showing each stage in action, what went right, what went wrong, and how each tool contributed.
The Project
Goal: Formalize components of the STOC 2025 paper “Privately Evaluating Untrusted Black-Box Functions” (Linder, Raskhodnikova, Smith, Steinke) using PCSAT/CHC constraint solvers.
Context: We had a mature CHC pipeline with 82+ verified encodings for relational array properties. We’d already verified histogram sensitivity=2, CDF sensitivity=m-1, and clipped sum sensitivity=B under the replace metric. The question: can we extend this to the paper’s new concepts (down sensitivity, inverse loss, privacy wrappers)?
Stage 0: FORMULATE (~15 min)
Hypothesis: We can use PCSAT/CHC to verify sensitivity properties
from the black-box DP paper.
Success: At least one non-trivial property verified (sat) with triple-probe.
Falsify: If PCSAT can't express delete-metric neighbors, pivot to Lean.
Cost: ~2 weeks of encoding work if wrong direction.
What happened: We read the 58-page paper, identified the key concepts (down sensitivity, inverse loss function, monotonization, privacy wrappers), and mapped each to “can CHC handle this?”
Tool used: Read (PDF pages), WebFetch (blog posts on down sensitivity and inverse sensitivity), /query-kb (searched personal knowledge base for CHC and DP entries).
Stage 1: FIND (~30 min)
Three search agents ran in parallel:
| Agent | Search Focus | Result |
|---|---|---|
| Agent 1 | Down sensitivity, inverse sensitivity, black-box DP | 15 papers on sensitivity mechanisms |
| Agent 2 | Formal verification of DP (CHC, HMC, LightDP, ShadowDP) | 20 papers on DP verification tools |
| Agent 3 | Most recent papers (2024-2026) citing the target paper | 12 recent papers including SampCert, Durfee 2025 |
Total: 36 papers across 6 clusters. Key finding: no existing tool formally verifies down sensitivity or inverse loss properties via CHC. This confirmed a genuine gap.
Tools used: Three parallel Agent subagents with WebSearch + WebFetch.
First Plan (Before JUDGE)
Based on FIND results, we built an initial to-do list:
| # | Target | What |
|---|---|---|
| P1 | Delete-metric encoding | Single-hole alignment for k=1 |
| P2 | Histogram down sensitivity ≤ 1 | Simple bin count under deletion |
| P3 | Clipped sum down sensitivity ≤ B | Already have replace-metric version |
| P4 | Average down sensitivity | Multiply out division |
| P5 | Inverse loss sensitivity 1 (Lemma 3.4) | For specific monotone f |
Codex consultation #1: Asked Codex to independently assess feasibility. Codex accepted the overall direction but flagged three corrections:
- Lemma 3.4 requires monotone f — average is NOT valid
- Single-hole alignment is better than two-counter async for k=1
- Subset-witness product is best for general k
We accepted all three corrections. The plan looked solid. We were ready to start encoding.
Then we ran the JUDGE stage.
Stage 2: JUDGE — The Pivot (~15 min)
Three review agents ran in parallel (background):
Agent 1: Hostile Peer Review (Reviewer #2)
The reviewer destroyed our plan. Key excerpts:
M1: “The five proposed targets are among the simplest lemmas in the paper. Histogram bin count has delete sensitivity 1 — this is a one-sentence observation. When the hand proof takes 6 lines and the machine encoding takes 80+ lines of .clp, the burden-of-proof question inverts.”
M2: “Verifying building blocks while leaving wrappers unverified is like verifying addition and claiming you verified a compiler. The building blocks are the part nobody doubts.”
M4: “If you instantiate f = count_above_threshold for the inverse loss, then sensitivity 1 reduces to verifying bin count sensitivity, which is already Target 1. This is circular.”
Verdict: MAJOR REVISION. The reviewer suggested completely different targets: Lemma 4.2 (interleaving of stabilization), Lemma D.4 (offset interleaving), and reframing the encoding pattern itself as the contribution.
Agent 2: Tool Comparison
Confirmed PCSAT is the right tool for loop-program sensitivity, but independently concluded that Lemma 3.4’s general statement needs Lean 4, not PCSAT. Also confirmed HMC, LightDP, ShadowDP solve fundamentally different problems.
Agent 3: Encoding Research
Found that the single-hole alignment is sound (universal quantification of h is correct), discovered that the three-case split collapses to two cases (before/after deletion are identical), and confirmed no existing CHC benchmark handles asymmetric-size relational properties.
Total time for JUDGE: ~15 minutes. The three agents ran in parallel in the background.
The Pivot
The JUDGE stage completely changed our direction:
| Before JUDGE | After JUDGE |
|---|---|
| 5 easy sensitivity bounds | Structural lemmas (4.2, D.4) |
| “We verified 5 lemmas” | “We introduce a new CHC encoding pattern” |
| Lemma 3.4 for one specific f | Lemma 3.4 generically in Lean |
| Target: DP venue (PETS, CSF) | Target: verification venue (VMCAI, CAV) |
Stage 3: VERIFY — Codex Confirms the Pivot (~10 min)
We presented three research framings to Codex for independent assessment:
- Framing A: First CHC encoding for delete-metric sensitivity (VMCAI)
- Framing B: Machine-verified building blocks for black-box DP (CSF/PETS)
- Framing C: Operationalize set-theoretic DP proofs as CHC (POPL/PLDI)
Codex’s response:
- Endorsed Framing A — “can stand alone if encoding theorem is clean”
- Rejected Framing C for POPL/PLDI — “overreaches technically and editorially”
- Proposed Framing D (new!) — “Proof-producing certification: CHC certificates → Lean checker → compose with SampCert” — this directly addresses the “gap between building blocks and wrapper” criticism
Nobody — not Claude, not the human — had thought of Framing D. It emerged from the VERIFY stage because Codex approached the problem from a different angle.
Final Consensus
| Framing | Venue | Status | Dependencies |
|---|---|---|---|
| A: Delete-metric CHC encoding | VMCAI | Start here | None |
| D: Certification + SampCert bridge | CAV short | After A | Blocked by A |
| B: Application story | Workshop | After A+D | Blocked by A, D |
| C: Set-theoretic lemmas | VMCAI/CAV | Side quest | Lemma D.4 only |
Stage 5: MONITOR (Ongoing)
Set up 4 scheduled remote agents:
| Time (ET) | Agent | Job |
|---|---|---|
| 12:00am | Research monitor | Scan for new papers on down sensitivity, CHC |
| 4:00am | Overnight worker | Execute to-do items with verification requirement |
| 5:00am | Deep-dive | Research encoding strategies for current priority |
| 10:00am | Morning briefer | Daily priority + new developments + blockers |
Each agent has a verification rule: cross-reference findings before saving, mark unverified claims.
Stage 6: RECORD
All decisions were recorded in:
- Project memory:
~/.claude/projects/.../memory/project_blackbox_dp_paper.md— tracks framings, consensus, corrections - Feedback memory:
~/.claude/projects/.../memory/feedback_research_workflow.md— captures the workflow itself for future reuse - Design doc:
docs/plans/2026-04-24-formalization-plan.md— the full formalization plan with encoding sketches
Timeline Summary
11:00pm FORMULATE: Read paper, define hypothesis 15 min
11:15pm FIND: 3 parallel search agents → 36 papers 30 min
11:45pm First plan: 5 targets (P1-P5) 10 min
11:55pm Codex #1: feasibility check → 3 corrections 10 min
12:05am JUDGE: 3 parallel review agents 15 min
├── Reviewer #2: "targets are trivially true"
├── Tool comparison: "use Lean for Lemma 3.4"
└── Encoding research: "2 cases not 3, j is redundant"
12:20am Pivot: completely revised direction 10 min
12:30am VERIFY: Codex #2 reviews 3 framings 10 min
└── Endorses A, rejects C for POPL, proposes D
12:40am Final consensus: 4 framings with execution order 5 min
12:45am MONITOR: Set up 4 scheduled agents 10 min
12:55am RECORD: Update memory, write design doc 15 min
─────────────────────────────────────────────────────────────────
Total: ~2 hours from paper to validated research plan
What Would Have Happened WITHOUT the Workflow
Without the JUDGE stage, we would have spent 1-2 weeks encoding histogram and clipped sum sensitivity under the delete metric — properties that are “one-sentence observations” according to Reviewer #2. We would have gotten sat from PCSAT, celebrated, written up 5 verified lemmas, submitted to a venue, and received the exact same hostile review… except 2 weeks later, with sunk cost making it harder to pivot.
The workflow cost ~30 extra minutes (JUDGE + VERIFY) and redirected the entire project toward a stronger contribution before a single line of .clp was written.
Lessons Learned
- The JUDGE stage paid for itself 100x. Four minutes of hostile peer review prevented weeks of wrong-direction work.
- Codex proposed something nobody else thought of. Framing D (proof-producing certification) emerged because Codex approached from a different angle than Claude.
- The first plan is usually wrong. Our 5-target plan looked solid after FIND + Codex #1. It took JUDGE to reveal it was targeting trivially true properties.
- Parallel agents are cheap insurance. Three background agents running for 15 minutes found: wrong targets, wrong tool for one subproblem, simpler encoding than planned.
- Record rejected alternatives. We rejected Framing C for POPL/PLDI, but recorded why — so future-us doesn’t waste time re-exploring that path.
How LearnAI Team Could Use This
The LearnAI team can apply this pipeline when deciding which AI research topics, tutorials, or tool workflows deserve deeper investment. Use FORMULATE to define the learning or research objective, FIND to collect papers and prior LearnAI notes, JUDGE to stress-test whether the direction is actually valuable, VERIFY to confirm with independent sources or tools, EXECUTE to build the artifact, MONITOR to track updates, and RECORD to preserve decisions for future contributors.
Real-World Use Cases
- Evaluating whether a new paper is worth turning into a LearnAI tutorial or implementation guide.
- Stress-testing a research plan before spending weeks building experiments or formal encodings.
- Comparing AI research tools such as Claude Code, Codex, Feynman skills, and autoresearch for a specific project.
- Setting up scheduled monitoring for fast-moving paper areas, benchmarks, or tool releases.
- Recording rejected directions so future LearnAI contributors do not repeat already-invalidated work.
How to Use This Workflow in Your Own Projects
The workflow lives at ~/.claude/RESEARCH_WORKFLOW.md — a global file accessible from any Claude Code project.
Quick Start (say this at the start of a session)
Follow the research workflow in ~/.claude/RESEARCH_WORKFLOW.md
That’s it. Claude will read the file and follow the full pipeline.
Common Prompts for Specific Stages
| Scenario | What to say |
|---|---|
| New paper/topic | I want to explore [paper/topic]. Follow ~/.claude/RESEARCH_WORKFLOW.md — start from FORMULATE. |
| Already have a plan | Here's my plan: [plan]. Run the JUDGE stage from ~/.claude/RESEARCH_WORKFLOW.md — peer review, tool comparison, deep dive, all in parallel. |
| Just need hostile review | Run a hostile Reviewer #2 on this plan: [plan]. Be brutal. |
| Set up monitoring | Set up the MONITOR stage from ~/.claude/RESEARCH_WORKFLOW.md for this project. |
| Check with Codex | Run the VERIFY stage — ask Codex if it agrees with this direction. |
| Start execution loop | Run the EXECUTE stage — set up autoresearch for [metric]. |
Make It Automatic (No Prompt Needed)
Add one line to any project’s CLAUDE.md file:
# Research Workflow
Follow ~/.claude/RESEARCH_WORKFLOW.md for all research tasks.
Every session in that project will follow the pipeline by default — no need to remember to ask.
Adapting for Different Research Types
Add the profile to your CLAUDE.md:
# Research Workflow
Follow ~/.claude/RESEARCH_WORKFLOW.md with the THEORY-HEAVY profile.
Available profiles: THEORY-HEAVY (critique-heavy, light execution), EMPIRICAL-HEAVY (early exploration, heavy monitoring), ENGINEERING-HEAVY (compressed FIND, heavy execution).