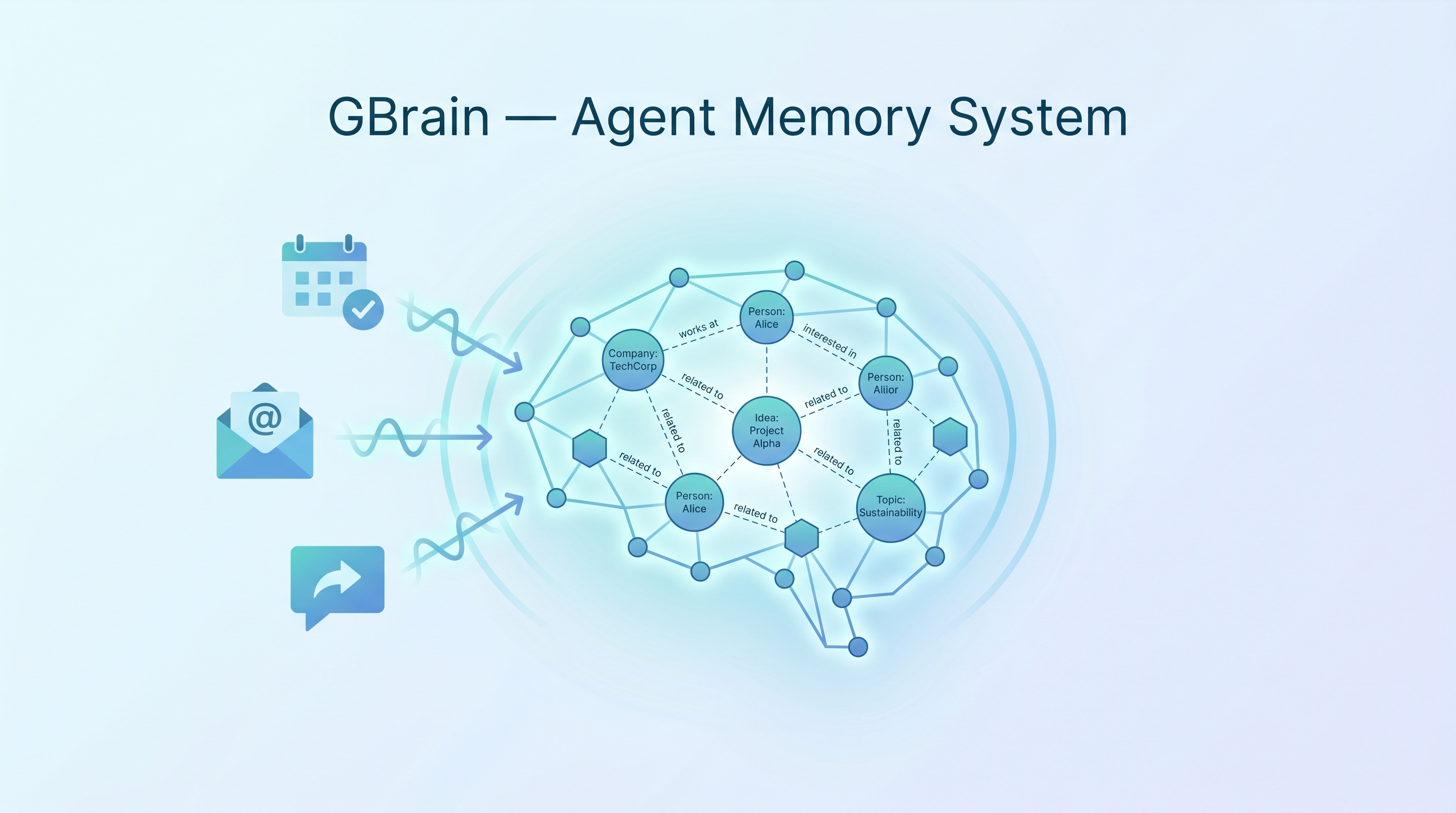
GBrain is a persistent memory and knowledge system built by Garry Tan (Y Combinator CEO) to power his autonomous agents. The core premise: “Your AI agent is smart but forgetful. GBrain gives it a brain.” In production, it manages 17,888 pages, 4,383 people, 723 companies, and runs 21 autonomous cron jobs — built in 12 days. With ~11.5k GitHub stars, it’s become one of the most prominent agent memory frameworks.
| *Source: GitHub - garrytan/gbrain | Hermes Agent listing | BrainBench benchmarks* |
Architecture
GBrain combines vector search with a self-wiring knowledge graph. Every write automatically extracts entities and creates typed links — no LLM calls needed for linking.
Signal arrives (meeting, email, social mention)
↓
Signal detector captures entities (parallel, non-blocking)
↓
Brain-ops: search brain first (gbrain search, gbrain get)
↓
Respond with full context
↓
Write updates with citations
↓
Auto-link extracts typed relationships (zero LLM calls)
↓
Sync indexes → knowledge compounds daily
Three-tier entity enrichment:
| Tier | Trigger | Action |
|---|---|---|
| Stub | First mention | Creates basic page |
| Enriched | 3+ cross-source mentions | Web/social enrichment triggers |
| Full (Tier 1) | Meeting or 8+ mentions | Complete processing |
Retrieval benchmarks: P@5 49.1%, R@5 97.9% — beats vector-only RAG by 31.4 percentage points.
Key Design Principles
Thin Harness, Fat Skills: Intelligence lives in skill markdown files, not the runtime. 29 curated skills encode entire workflows with triggers, quality gates, and chaining logic.
Brain-First: Agents check the brain before calling external APIs. Reduces tokens, latency, and hallucinations.
Determinism > Reasoning: Deterministic work (parsing, linking) uses TypeScript; judgment calls (routing, enrichment) use LLMs. Prevents the “reasoning model for deterministic tasks” anti-pattern.
Minions: Durable Job Queue
GBrain replaces unreliable sub-agent spawning with Postgres-native background jobs:
| Metric | Minions | Sub-agent Spawn |
|---|---|---|
| Wall time (single job) | 753ms | 10,000+ ms (timeout) |
| Token cost | $0 | ~$0.03 |
| Success rate | 100% | ~60% |
| Large batch (19,240 posts) | ~15 min, $0.00 | ~9 min, $1.08, 40% failures |
Installation
# Agent platform (OpenClaw/Hermes) — paste into agent:
# "Retrieve and follow: https://raw.githubusercontent.com/garrytan/gbrain/master/INSTALL_FOR_AGENTS.md"
# Standalone CLI
git clone https://github.com/garrytan/gbrain.git && cd gbrain
bun install && bun link
gbrain init # Database ready in 2 seconds (PGLite embedded)
# MCP Server (Claude Code, Cursor, Windsurf)
# Add to MCP config: {"mcpServers": {"gbrain": {"command": "gbrain", "args": ["serve"]}}}
Imports from Obsidian, Notion, Logseq, markdown, CSV, JSON, and Roam.
How LearnAI Team Could Use This
- Persistent research memory — accumulate knowledge across meetings, papers, and projects that agents can query
- Relationship tracking — auto-link people, papers, and research topics without manual effort
- Teaching case study — demonstrates the “thin harness, fat skills” architecture for agent design courses
- Inspiration for knowledge management — the three-tier enrichment pattern applies to any knowledge base
Real-World Use Cases
- VC/startup ecosystem — Garry Tan uses it to track 4,383 people and 723 companies across YC
- Research labs — persistent memory for multi-project, multi-collaborator environments
- Personal knowledge management — replaces scattered notes with a queryable, auto-enriching brain
- Agent infrastructure — any agent system that needs durable, growing memory