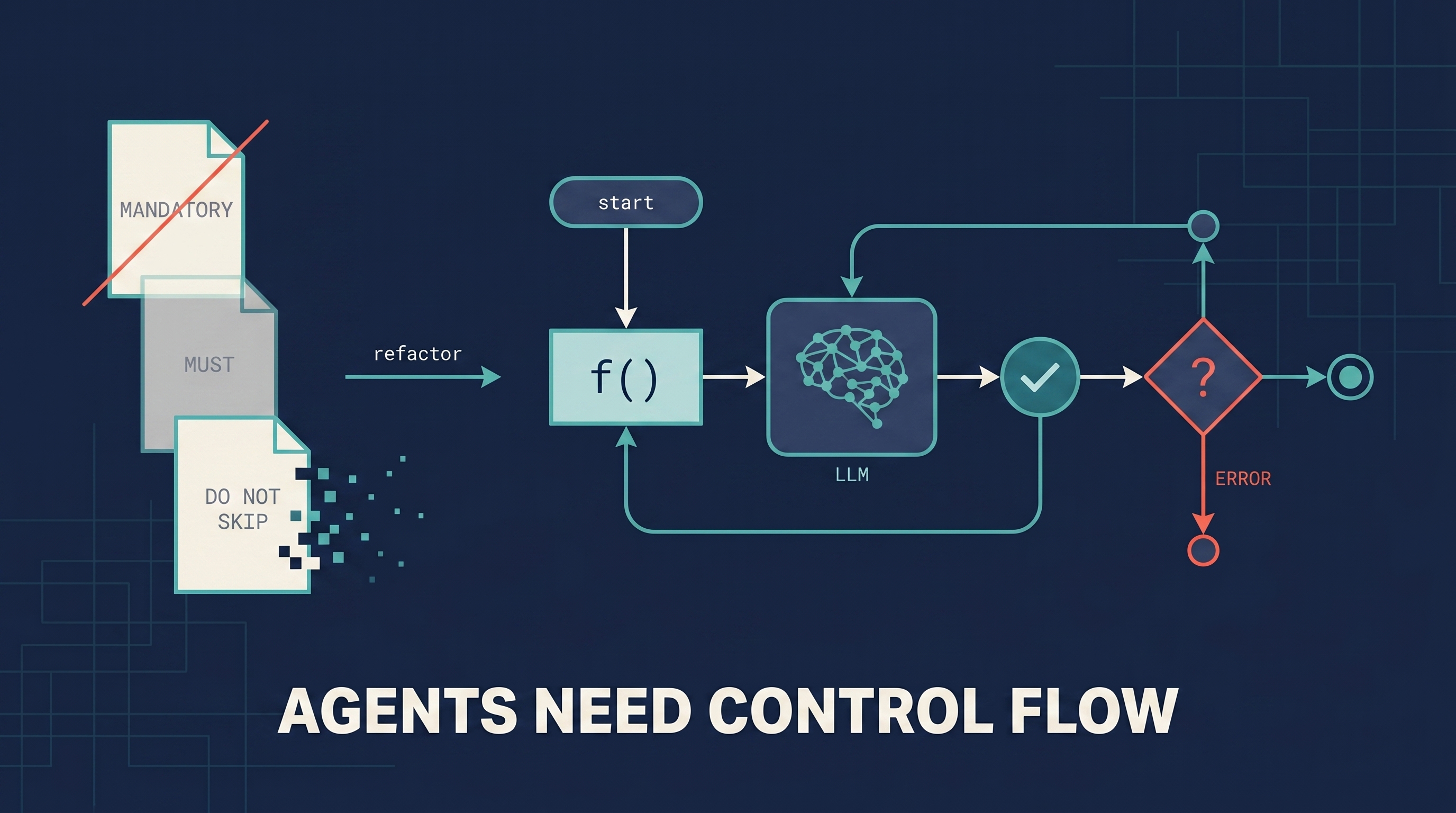
A short essay published in May 2026 at bsuh.bearblog.dev (the author signs as “brian”) that crystallizes a thesis the agent community has been circling for a year: reliable agents need explicit software control flow, not increasingly emphatic prompt directives. It opens with an analogy that does most of the work: imagine a programming language where statements are suggestions and functions return “Success” while hallucinating. That is what every “MANDATORY” / “DO NOT SKIP” / “you MUST” prompt is pretending isn’t true. The fix is mundane and old-school: deterministic scaffolds — state transitions, validation checkpoints, code-level constraints — that treat the LLM as a component, not the entire system.
| *Source: “Agents Need Control Flow, Not More Prompts” — bsuh.bearblog.dev | Weibo coverage by 爱可可-爱生活* |
The Opening Analogy
“Imagine a programming language where statements are suggestions and functions return ‘Success’ while hallucinating.”
In Brian’s framing this is what prompt-only agent control actually is. Add a “MUST” in caps to the system prompt and the model treats it as a strong suggestion, not an enforced rule. Reasoning about correctness becomes impossible. Reliability collapses as system complexity grows. The leak is structural, not stylistic — you can’t fix it by writing more emphatic prompts.
The Three Failure Modes Without Programmatic Verification
When you rely on prompt directives alone, Brian argues you’re left with three options for catching the agent’s mistakes:
| Mode | What It Means | Cost |
|---|---|---|
| Babysitter | A human watches every step and intervenes when the agent drifts | Doesn’t scale — the human becomes the bottleneck |
| Auditor | Exhaustive post-run verification of every output | Expensive, slow, and the audit itself can miss subtle errors |
| Prayer | Accept whatever comes out without verification | The path most teams end up on when neither babysitting nor auditing is sustainable |
None of these are real engineering. They’re stopgaps for a missing primitive.
The Fix: Deterministic Scaffolds
Brian’s prescription:
“Reliable agents tackling complex tasks need deterministic control flow encoded in software, not increasingly elaborate prompt chains.”
Concretely:
- Explicit state transitions — a state machine defines which steps can follow which other steps; the model can only pick from the valid next set
- Validation checkpoints — between each model call, run a deterministic check; on failure, retry / branch / escalate instead of letting the error compound
- LLM as component, not system — the language model is one node in your graph, not the orchestrator. The orchestrator is code you control.
The closing reminder: deterministic orchestration is only half the battle. If your validation checks are too permissive, the system happily reaches the wrong conclusion. “Aggressive error detection” is the other half — better to fail loudly than to ship silently-wrong output.
Why This Lands
The thesis isn’t new. Anthropic’s harness-engineering posts make a related argument; the Vercel finding cited in Harness Engineering (Pillar 2) — that removing ~80% of tools made agents faster and more reliable — points the same way. What this essay adds is a memorable framing:
| Framing | Effect |
|---|---|
| “Statements are suggestions” | Names the leak: prompts have no enforcement contract |
| “Functions return ‘Success’ while hallucinating” | Names the verification gap |
| “Babysitter / Auditor / Prayer” | Names the three sub-optimal alternatives |
| “LLM as component, not system” | Hands you the design rule in one phrase |
The harness-engineering literature is detailed and technical; this essay condenses the same argument into a form that’s easier to point teammates at.
How It Slots into the Harness Engineering Picture
This entry is a narrow companion to Harness Engineering — The Real Bottleneck Isn’t the Model. That entry’s Pillar 2 (“Architectural Constraints — Code Rules > Prompt Suggestions”) makes the same point at length. The bearblog essay is a short, single-thesis version of it.
┌─ Harness Engineering (the full system)
│
├── Pillar 1: Context Architecture
├── Pillar 2: Architectural Constraints ← this essay lives here
├── Pillar 3: Reasoning Phases
├── Pillar 4: Subagents as Context Firewalls
├── Pillar 5: Entropy Governance
└── Pillar 6: Modular Middleware
If your team is new to the concept, lead with this entry. Once the framing lands, follow up with the harness pillars for the full architecture.
Practical Translation — From Prompt to Control Flow
A representative refactor:
Before (prompt-only):
You are a code review agent. MANDATORY: always run tests before
approving a PR. DO NOT SKIP this step. If tests fail, you MUST
report the failure. NEVER mark a PR as approved without running
tests first.
After (control flow + validated schema):
from enum import Enum
from pydantic import BaseModel
class Risk(str, Enum):
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
class RiskJudgment(BaseModel):
level: Risk # constrained to the enum above
rationale: str
# Code controls the flow; the model only fills in two narrow decision nodes
def review_pr(pr):
diff = git_diff(pr)
analysis = llm("analyze this diff", diff) # model is a tool here
test_result = run_tests(pr) # deterministic
if not test_result.passed:
return reject(pr, test_result.failures) # deterministic
judgment: RiskJudgment = llm_structured( # schema-validated call
"Classify merge risk: low | medium | high.",
inputs=[diff, analysis],
schema=RiskJudgment,
)
if judgment.level == Risk.HIGH:
return request_human_review(pr, judgment.rationale) # deterministic
return approve(pr) # deterministic
In the second version, the “MANDATORY: run tests” rule isn’t a prompt — it’s a function call the agent can’t route around. Equally important: the model’s risk judgment is constrained to a typed enum via llm_structured (pydantic / JSON schema), so a free-form “high-ish” string can’t slip past the if check. The model still makes two judgment calls, but each is scoped to a validated output type.
Caveats Worth Stating
- Some tasks resist control flow. Open-ended exploration (“research X and write a report”) is genuinely hard to decompose into state machines. Brian’s argument is strongest for reliability-critical, repeatable workflows.
- Over-constraining is its own failure. A state machine that only allows the model to pick from 3 next-steps eliminates the flexibility that made you want an agent in the first place. The Bitter Lesson applies — don’t over-engineer scaffolds the next model will obsolete.
- Validation is hard. Brian’s closing caveat — that aggressive error detection matters as much as orchestration — is the part most engineers underestimate. A control flow with weak validators is just slower prayer.
How LearnAI Team Could Use This
- First-principles lesson on agent reliability. A short single-thesis essay — fits as an opening reading before any agent-engineering module.
- Refactor exercise. Give students a prompt-heavy agent (“you MUST do X, NEVER do Y, ALWAYS verify Z”) and ask them to convert it into a control flow with validation checkpoints. Compare reliability before/after on a fixed test set.
- Decision rubric. Teach students the question: “If this step fails silently, what’s my recovery path?” If the answer is “I’d never notice,” the step needs a deterministic check.
- Pair with harness engineering for full depth. Use this entry as the gateway and the harness-engineering entry for the architecture.
Real-World Use Cases
- CI/CD agents — instead of prompting “MUST run tests before deploying,” wrap the deploy step in code that calls the model only for narrow decisions (rollback strategy, release notes). Deterministic gates handle the rest.
- Customer support agents — instead of “DO NOT promise refunds you can’t authorize,” put the refund-authorization step behind a function the model has to call; the function enforces the policy.
- Data pipeline agents — instead of “ALWAYS validate the schema,” validate the schema in code; the model only handles transformation logic.
- Research agents — exploration phases tolerate looser control, but the synthesis-and-cite phase benefits from explicit checks (“every claim must trace to a fetched URL”; enforced in code, not prompt).
- Code-review bots — see the refactor example above; the model’s role shrinks from “do the whole review” to “make two specific judgment calls.”
Links
- Brian’s essay: Agents Need Control Flow, Not More Prompts — bsuh.bearblog.dev
- Companion entry: Harness Engineering — The Real Bottleneck Isn’t the Model (Pillar 2 is the long-form version of Brian’s thesis)
- Related reading: Seeing Like an Agent — How Anthropic Designs Tools for Claude Code, SpecOps — Spec-Driven Development with AI Coding Agents