
Claude Mythos Preview is Anthropic’s restricted-access frontier model for AI-assisted cybersecurity. The controversy around it is not simply whether AI can find vulnerabilities. The useful lesson is sharper: when a vendor frames a model as risky enough to restrict access, the public evidence must be strong enough to support the resulting governance, funding, and access-control decisions.
| *Source: The Boy That Cried Mythos | Project Glasswing | Claude Mythos Preview System Card | AISI evaluation | AISLE: The Jagged Frontier* |
The Core Concept
The FlyingPenguin article argues that Anthropic’s Mythos story has a verification problem: the strongest public claims come from launch posts and partner-program materials, while the technical artifact is narrower, harder to reproduce, and less complete than the headlines imply.
That does not mean Mythos is useless. The system card, AISI evaluation, and Anthropic updates all show real cyber capability. The issue is whether the evidence supports the larger conclusion: restricted access, policy urgency, funding decisions, and a restricted partner network around a model framed as requiring special handling because of cyber risk.
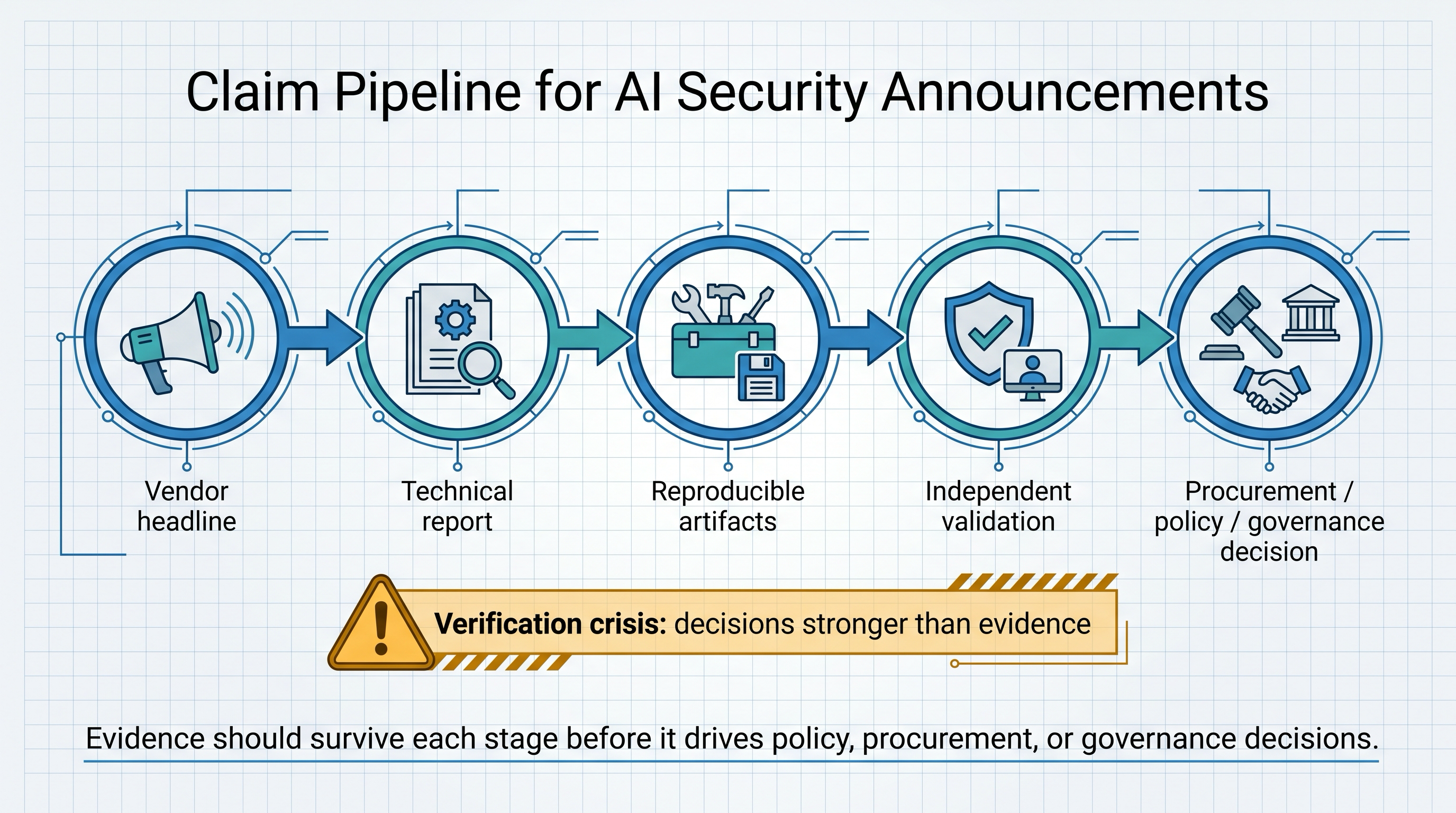
Claim pipeline for AI security announcements
Vendor headline
|
v
Technical report
|
v
Reproducible artifacts
|
v
Independent validation
|
v
Procurement / policy / governance decision
Verification crisis = a later decision is much stronger than the evidence
that survived the earlier steps.
For a security claim, “we found many bugs” is only the start. A strong evidence package needs CVE identifiers, severity distribution, reproduction steps, disclosure timelines, duplicate and false-positive rates, baseline comparisons against existing tools, and vendor or maintainer confirmation.
What Mythos Actually Demonstrated
Anthropic’s own system card says Mythos is its most cyber-capable model and reports improvement across several cyber tasks. The important part is to read the evaluations by what they measure, not by what a headline wants them to imply.
| Evidence | What it supports | What it does not fully prove |
|---|---|---|
| Cybench | Mythos saturates a public CTF-style benchmark | That Mythos can autonomously find real-world zero-days at scale |
| CyberGym | Mythos improves targeted reproduction of previously discovered vulnerabilities | That it discovers unknown vulnerabilities without strong hints |
| System-card Firefox 147 shell evaluation | Mythos can turn selected crash categories into exploit primitives in a stripped-down harness | That it compromised a fully defended browser environment |
| AISI cyber range | Mythos completed one 32-step weakly defended corporate-network simulation in 3 of 10 runs | That it can attack well-defended production networks |
| Glasswing update | Anthropic and partners report large-scale vulnerability discovery and triage activity | That the full model-generated count is independently verified |
The Firefox evaluation is the cleanest example of why wording matters. The system card describes a Firefox 147 setup where the model receives 50 crash categories discovered by Claude Opus 4.6, runs inside a SpiderMonkey shell, and uses a harness without the browser’s normal process sandbox and other defense-in-depth mitigations. Mythos performs much better than prior Claude models in that setup, but the setup is not the same as “the model broke modern Firefox in the wild.”
The AISI evaluation is similarly important and bounded. AISI found that Mythos was a step up over prior frontier models, including 73% success on expert CTF tasks and completion of “The Last Ones” corporate-network range in 3 of 10 attempts. But AISI also states that the range lacks active defenders and defensive tooling, so it cannot conclude Mythos would succeed against well-defended systems.
Where Verification Breaks Down
FlyingPenguin’s critique is useful because it names the missing receipts. Anthropic’s Glasswing launch page says Mythos had already found “thousands of high-severity vulnerabilities” including some “in every major operating system and web browser.” For a claim that strong, the public package should let outsiders trace the path from model output to confirmed vulnerability.
Some details can be withheld for legitimate safety and coordinated-disclosure reasons. But the less detail that can be public, the more important it becomes to provide trusted third-party validation, clear methodology, representative aggregate statistics, and a disclosure path that outsiders can audit later.
Weak evidence chain
"Thousands" headline
|
+--> no public CVE list for the full claim
+--> no full severity distribution
+--> no reproducible harness for outsiders
+--> no baseline against fuzzers / SAST / CodeQL-style tools
+--> no public false-positive rate over all raw model findings
+--> limited partner-level confirmation of specific findings
Anthropic’s May 22 Glasswing update adds more concrete data, but it also shows why the verification question remains open. Anthropic reports 23,019 total open-source findings, 6,202 estimated high or critical by Mythos, 1,752 high/critical-rated findings carefully assessed by humans or security firms, 90.6% true positives among that assessed subset, and 75 high/critical bugs patched by that point. That is meaningful evidence, but the 90.6% figure applies to the reviewed subset, not automatically to every raw model finding. Because the assessed subset was likely prioritized for review, it should not be treated as a random sample of all 23,019 findings.
Independent checks complicate the “frontier-exclusive” framing. AISLE tested Anthropic’s showcased vulnerabilities with cheaper open-weight models and found that eight out of eight models detected the flagship FreeBSD NFS issue, including GPT-OSS-20b with 3.6B active parameters at $0.11 per million tokens. Cisco later described its own AI security work as model-agnostic: the model is an accelerant, while the harness is the engine.
These reproductions do not prove that smaller models match Mythos across the full exploit-development workflow. They show that some showcased detections may depend heavily on harness design, target selection, and the surrounding security process.
The emerging pattern is that the system around the model matters as much as the model itself:
Security result = model + harness + target selection + oracle + human review + patch workflow
If only the model is discussed, the capability story is underspecified.
If only the output count is discussed, the security impact is underspecified.
If only discovery is discussed, the defender value is underspecified.
How To Read AI Security Claims
Use Mythos as a checklist for future announcements. The right question is not “is the model impressive?” It is “what evidence would make this claim decision-grade?”
| Ask for | Why it matters |
|---|---|
| Public CVE or advisory mapping | Separates model-generated reports from confirmed vulnerabilities |
| Reproduction steps | Lets independent researchers verify novelty and exploitability |
| Severity distribution | Prevents one dramatic example from standing in for the whole dataset |
| False-positive and duplicate rates | Measures triage load, not just discovery volume |
| Baselines against fuzzers and static analyzers | Shows whether the AI found what existing tools miss |
| Patch velocity | Tests the defensive story directly |
| Maintainer or vendor confirmation | Anchors claims outside the vendor’s own marketing loop |
| Cost per validated finding | Reveals whether a restricted-access or high-cost model is economically justified |
The most practical takeaway for defenders is boring and important: AI-assisted vulnerability discovery raises the value of patching discipline, asset inventory, EDR coverage, logging, segmentation, and secure-by-default configuration. If discovery accelerates but verification and patching do not, the backlog grows faster.
For teaching and research, this is a strong case study in evidence literacy. Students can compare a launch blog, a system card, an independent government evaluation, an independent reproduction attempt, and a vendor update. The exercise is not to decide whether Anthropic is “right” or “wrong.” The exercise is to identify which claims are supported, which are plausible but not yet verified, and which are policy conclusions masquerading as technical facts.
Important Things To Know
| Misread | Better reading |
|---|---|
| “Mythos is fake” | No. Public evidence shows real improvements in cyber tasks. |
| “The headlines are proven” | Not fully. Some headline claims remain hard to independently verify. |
| “Open models make Mythos irrelevant” | Not exactly. They weaken the claim that capability is frontier-exclusive, but harness quality still matters. |
| “More bug discovery automatically helps defenders” | Only if triage, disclosure, patching, and deployment also speed up. |
| “A restricted partner program is just safety” | Maybe, but selective access to vulnerability-discovery capability is also a governance and market-power decision. |
As of June 8, 2026, the prudent posture is provisional: treat Mythos as a serious AI security capability, but do not let unverified counts or high-urgency framing substitute for reproducible evidence.
Further Reading
- Project Glasswing: An initial update - Anthropic’s May 22 update with raw counts, reviewed-subset figures, disclosure status, and patching bottleneck.
- Expanding Project Glasswing - Anthropic’s June 2 expansion to about 150 additional organizations.
- 8 Years of Security Research in 8 Weeks - Cisco’s model-agnostic framing around the Foundry Security Spec.
- Executive Summary for Claude Mythos Project Glasswing: June 2026 Verification Status - FlyingPenguin’s June 8 status update and critique.