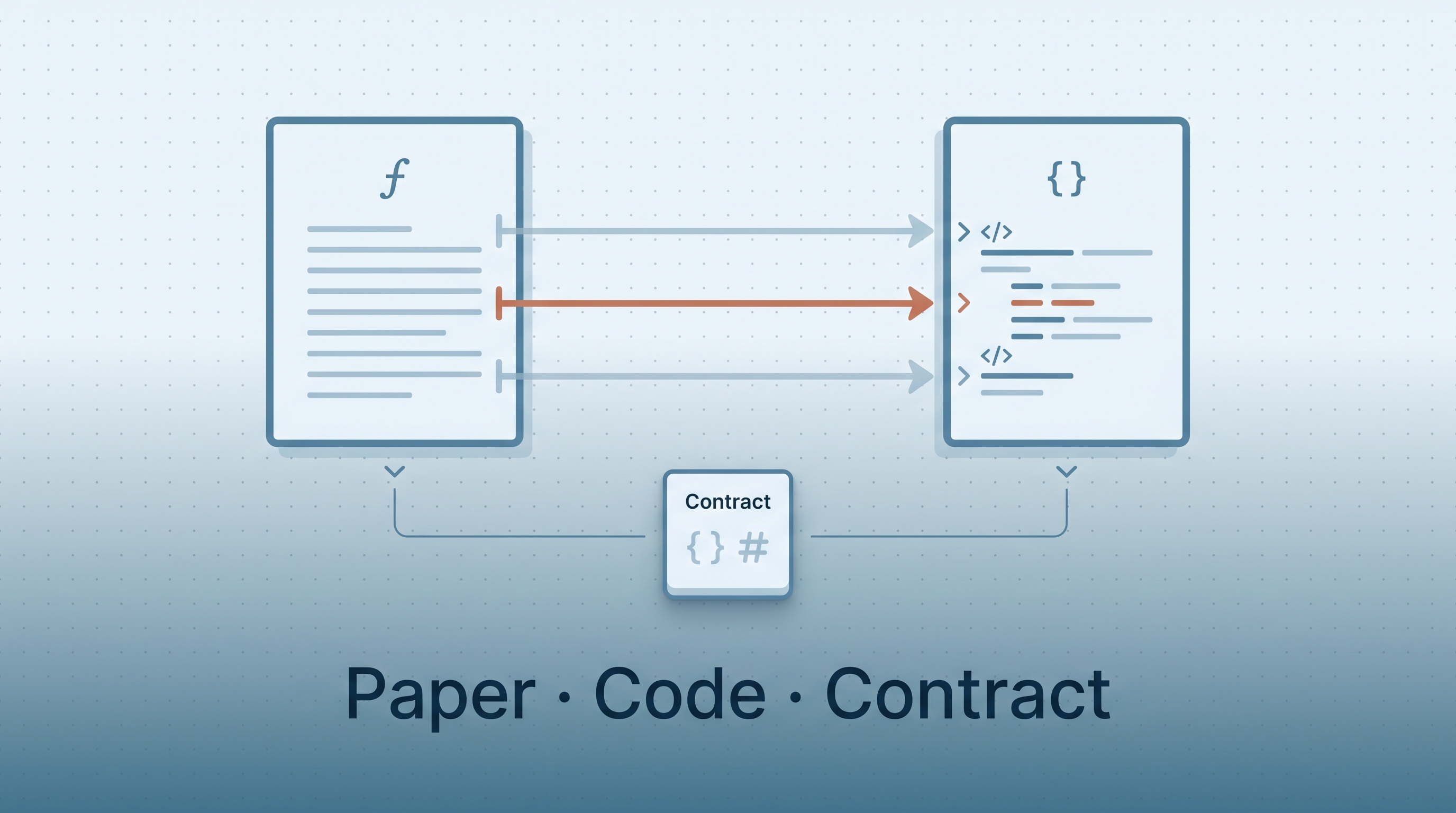
Paper-Code Joint Analysis by c-narcissus (README declares MIT-0; ~0 stars as of May 18, 2026 — early days) is a Codex-only skill that takes a research paper plus its open-source implementation and produces a structured artifact set mapping paper content (formulas, algorithms, experimental setups) to actual code (files, classes, methods, parameters, commands), capped off with a static HTML reader. The skill is a useful tool, but the more transferable contribution is its companion file — contract_driven_reusable_skill_methodology.md — which formalizes a contract-driven approach to designing reusable Codex / Claude Code skills: define stable artifact contracts (JSON bundle + fixed Markdown filenames) first, then layer analysis logic on top, so the renderer never needs per-project changes. This entry covers both: the skill as a worked example, the methodology as a transferable pattern.
| *Source: github.com/c-narcissus/paper-code-joint-analysis-skill (README declares MIT-0) | Companion: contract_driven_reusable_skill_methodology.md |
Worked example credit: Xinyang Liu from Bristol (SemiDFL paper)* |
Part 1 — The skill: what it produces
You hand Codex three things:
- A paper (PDF, arXiv link, or just a title)
- The paper’s open-source code (GitHub URL or local path)
- The skill’s zip file
You prompt Codex with something like “Please use paper-code-joint-analysis to jointly analyze [paper] and [code].”
What you get back is a set of root-level artifacts in your workspace plus an optional static reader:
| Artifact | Role |
|---|---|
analysis_bundle.json |
Machine-readable bundle (the contract) |
paper_reading_report.md |
Deep-reading report of the paper |
paper_questions_for_code.md |
Open questions to ask of the code |
paper_code_crosswalk.md |
Paper element ↔ code symbol mappings |
experiment_joint_reading.md |
Experiments cross-referenced to runnable commands |
implementation_omissions.md |
Things the paper omits that the code reveals |
diagrams.md |
UML / sequence diagrams (Mermaid) |
modify_method_guide.md |
“How to modify this method” guide |
validation_report.md |
Output validation against the declared contract |
site/index.html |
Static reader that renders the above |
You can annotate passages directly in Codex’s web viewer and ask follow-up questions on selected text.
Part 2 — How it compares to Paper2Code (a related tool)
Paper2Code (Pratham Goradia / PrathamLearnsToCode/paper2code, ~1.3k stars, MIT) lives nearby in the “research-paper-meets-AI” space, but they answer different questions:
| Paper2Code (Pratham) | Paper-Code Joint Analysis (c-narcissus) | |
|---|---|---|
| Question it answers | “Implement this paper from scratch in Python” | “Help me understand this paper through its existing code” |
| Input | A paper only | A paper + its existing source repo |
| Output | Runnable Python project + walkthrough notebook | Structured Markdown + JSON artifacts + static HTML reader |
| Direction | paper → code | paper + code → joint understanding |
| Honesty mechanism | Ambiguity audit (specified / partial / unspecified) | Theory-to-code mapping with explicit gaps |
| Stack | Agent skill with Claude Code support (installable via npx skills add) |
Codex skill (Codex-only) |
| License / stars | MIT / ~1.3k | README declares MIT-0 / ~0 |
Use Paper2Code when you don’t have a reference implementation and need to bootstrap one. Use Paper-Code Joint Analysis when the implementation already exists and you want to learn the paper by mapping it onto that code.
Part 3 — The transferable lesson: contract-driven skill design
The companion methodology file argues that many skills get the order wrong: they hand-write per-project web pages and one-off report formats, which means every new analysis requires rewriting the renderer. The fix is to invert the order.
The author’s core claim (translated from the original Chinese):
“先定义稳定产物契约,再让不同分析模块把结果写入同一组人类可读和机器可读产物,最终由通用静态阅读器展示.”
“Define a stable artifact contract first, then have different analysis modules write results into the same set of human and machine-readable artifacts, finally displayed by a generic static reader.”
In practice, this means committing — up front, before any analysis code — to:
- A machine-readable bundle (e.g.,
analysis_bundle.json) - Fixed Markdown filenames and a stable schema version
- Required fields with declared semantics
- A static reader template that never changes per-project
The seven core principles (paraphrased)
| # | Principle | What it means |
|---|---|---|
| 1 | Contract-first | Define artifact contracts before writing analysis logic |
| 2 | Webpage is a template, not the result itself | Web/report interfaces are generic readers — they consume the artifacts, they don’t are the artifacts |
| 3 | Dual output | Always produce both human-readable Markdown and machine-readable JSON |
| 4 | Modularity | Decouple deep reading, code mapping, validation, and rendering into independent modules |
| 5 | Every complete output must be checkable | Schema validation, file checks, encoding verification, diagram-rendering checks |
| 6 | Stable expression | Standardized formats — math blocks for formulas, Mermaid for diagrams, structured tables for complex data |
| 7 | Reusability over one-off | Prioritize modular components over project-specific page code |
Worked examples of contracts in the methodology
The methodology gives example contracts (not full formal JSON schemas with field-by-field specs) for three skill families. The names below are what the methodology actually documents — treat them as templates you can adapt, not as the only correct filenames:
| Skill family | Example artifacts |
|---|---|
| Paper Analysis | (concrete instance in this skill: paper_reading_report.md, paper_questions_for_code.md, paper_code_crosswalk.md, analysis_bundle.json, site/index.html) |
| Review Analysis | review_report.md, claim_evidence_audit.md, weakness_matrix.md, rebuttal_suggestions.md, review_bundle.json, plus a static reader |
| Reproduction Analysis | environment_report.md, command_matrix.md, result_parser.md, reproduction_gaps.md, reproduce_bundle.json, plus a static reader |
Every analysis run for the same family targets the same declared bundle contract / schema family. The renderer doesn’t branch per-project.
How it differs from typical skill design
The methodology contrasts two approaches:
| Traditional approach | Contract-driven approach |
|---|---|
| Hand-write web pages for each project | Use a generic static reader template |
Rewrite index.html / app.js per case |
Modify the reader template once, apply everywhere |
| Only generate web output | Generate both Markdown and JSON |
| Project-specific logic embedded in page code | Move logic into modules and schema fields |
| No verification framework | Validate schema, files, encoding, formulas, resources |
Contract-driven design is, in spirit, schema-first software engineering applied to the skill layer — the same discipline the API-design world has practiced for years (OpenAPI / JSON Schema / typed bundles). It’s complementary to Anthropic’s progressive-disclosure pattern for skill inputs (see Thariq’s framework): progressive disclosure governs how the instructions reach the model; contract-driven design governs how the outputs are structured.
Install + usage
Per the README’s documented flow:
- Create an empty Codex workspace.
- Place the skill zip (
paper-code-joint-analysis.skill.zip), the paper, and the code in that directory. -
Prompt Codex:
“Please use
paper-code-joint-analysis.skill.zipto jointly analyze[paper-or-arxiv-link]and[github-url-or-local-path].” - Wait for the artifacts to appear at the workspace root. Open
site/index.htmlin a browser to read them through the static reader. Annotate, ask follow-ups.
The skill is not a CLI, Python library, browser extension, or standalone web app — it only runs inside Codex.
Teaching Mode — CS-336 (Program Analysis for Security) paper-reproduction lab
CS-336 at Monmouth is type systems / parsing / interpretation / information flow / taint analysis — so the lab should use program-analysis or security paper+code pairs, not ML papers. Plan for starter materials (a vetted list of 5-10 paper+code pairs in the program-analysis space, plus a sample contract).
Week 1 — Joint analysis as a literature-review aid (~2 hr lab)
| Activity | Output |
|---|---|
| Each student picks a paper+code pair from a vetted PL/security list (e.g., a published taint-analysis tool with a public repo, a small information-flow analyzer, a parsing-paper with a reference implementation) | Selected target |
| Run paper-code-joint-analysis on it; inspect the generated artifacts and HTML report | Annotated mapping report |
| In a 1-page reflection, identify three places where the paper omits implementation details the code reveals (or vice versa) | Concrete examples of paper-code divergence |
Week 2 — Contract design exercise (~3 hr lab; provide starter scaffolding)
| Activity | Output |
|---|---|
| Read the contract-driven methodology file | Students can name the 7 principles |
| Pick a different program-analysis workflow (e.g., “security audit of a single function,” “type-error explanation,” “taint-source enumeration”) and define an artifact contract for it — what Markdown files, what JSON bundle, what required fields | A 1-page contract spec |
| Using a provided starter (a tiny analyzer + the empty schema), implement a minimal skill that writes to that contract | Working skill with contract-validated output |
| Reflect: what’s reusable, what’s project-specific? | Vocabulary for thinking about skill design |
Assessment ideas
- Quiz (10 min): given two report directories (one contract-driven, one ad-hoc), identify which adheres to a contract and what specifically breaks reusability in the other.
- Lab grading rubric: did the student’s skill produce both Markdown and JSON? Does the JSON validate against their declared schema? Does the renderer template they wrote work without changes on a second paper+code pair?
How LearnAI Team Could Use This
- Companion to the Research-KB pipeline — pair with research-kb-zotero-obsidian: when a paper enters the KB and has a public implementation, run paper-code-joint-analysis to produce the mapping artifact alongside the Zotero entry. The JSON bundle slots cleanly into structured KB tooling.
- Faculty-training workshop on skill design — the contract-driven methodology is a useful “how to design skills well” lesson for colleagues now writing their own Codex / Claude skills. Half-day session: read the methodology, design a contract for a workflow you do weekly, implement it.
- CS-336 (Program Analysis for Security) — the contract pattern transfers directly: define a
vulnerability_bundle.jsonschema, then have any static-analysis tool you build target the same contract. Renderer once, analyzers many. - Student paper-reproduction labs — assign paper+code pairs from a program-analysis / security reading list; the skill output is a structured artifact you can grade against the contract rather than against free-form prose.
Real-World Use Cases
| Scenario | How to use |
|---|---|
| Reading a complex paper with public code | Run the skill; navigate paper-section-to-code-symbol mappings instead of context-switching between PDF and IDE |
| Onboarding a new collaborator to a research codebase | Generate the joint report; let the collaborator follow paper sections into code rather than browsing files cold |
| Writing a review for a paper that includes a repo | Use the review_report.md / weakness_matrix.md example contracts (or fork them) to ensure reviews cover claim-evidence consistency in a standardized way |
| Replication study scoping | Use the reproduction_gaps.md example contract to surface unspecified details before committing to a full reproduction effort |
| Designing a new agent skill | Use the contract-driven methodology as a checklist: define the artifact contract first, implement analysis second |
Limitations and honest caveats
- Codex-only. Doesn’t run in Claude Code, Cursor, or any other agent host today. If your team is on a non-Codex stack, you can still adopt the methodology but not this specific skill.
- Static analysis, no execution. The skill maps paper → code structurally; it does not run training or verify numerical reproduction. For numerical reproduction, layer on the
reproduction_gapscontract and an actual training run. - Depends on the implementation being readable and open. If the paper’s code is closed, proprietary, or substantially obfuscated, the skill’s mapping output will be sparse.
- Early days. ~0 stars at the time of writing; the skill works, but the ecosystem of “contract-driven skills” inspired by it is still nascent. Read the methodology as the idea; the skill is one early implementation.
- Schema versioning is on you. The methodology recommends a
schema_versionfield but the discipline of actually bumping it as your skill evolves is a humans-and-process problem the methodology can’t enforce. - The methodology provides example contracts, not formal JSON schemas. If you adopt it, you’ll need to spec out your own field-by-field schema with whatever rigor your use case needs.
Important things to know
- The methodology is the bigger insight; the skill is the worked example. Even if you never run paper-code-joint-analysis, the discipline of “define the artifact contract first, write analysis logic second” is a useful pattern for any skill that produces structured output.
- This composes with Anthropic’s progressive-disclosure pattern, not against it. Progressive disclosure governs how the instructions reach the model; contract-driven design governs how the outputs are structured. Both apply.
- The Markdown + JSON dual-output discipline is one of the principles worth applying immediately. Markdown for humans, JSON for tooling; skipping either leads to brittle skills.
- Companion deep-dives in this wiki:
- Paper2Code — Turn ArXiv Papers into Citation-Anchored Code — related tool, opposite direction
- academic-research-skills — Imbad0202’s 4-Skill Pipeline — broader research-skill collection
- AI Agents for Academic Research & Writing — the larger AI-for-research workflow context
- Building a Research KB — Zotero + Obsidian + Claude Code — the dual-layer KB this skill plugs into
- How Anthropic Uses Skills — Thariq’s Framework — the input-side counterpart (progressive disclosure)
- Karpathy Skills — Four Rules That Fix LLM Coding’s Worst Habits — adjacent philosophy on small composable skills