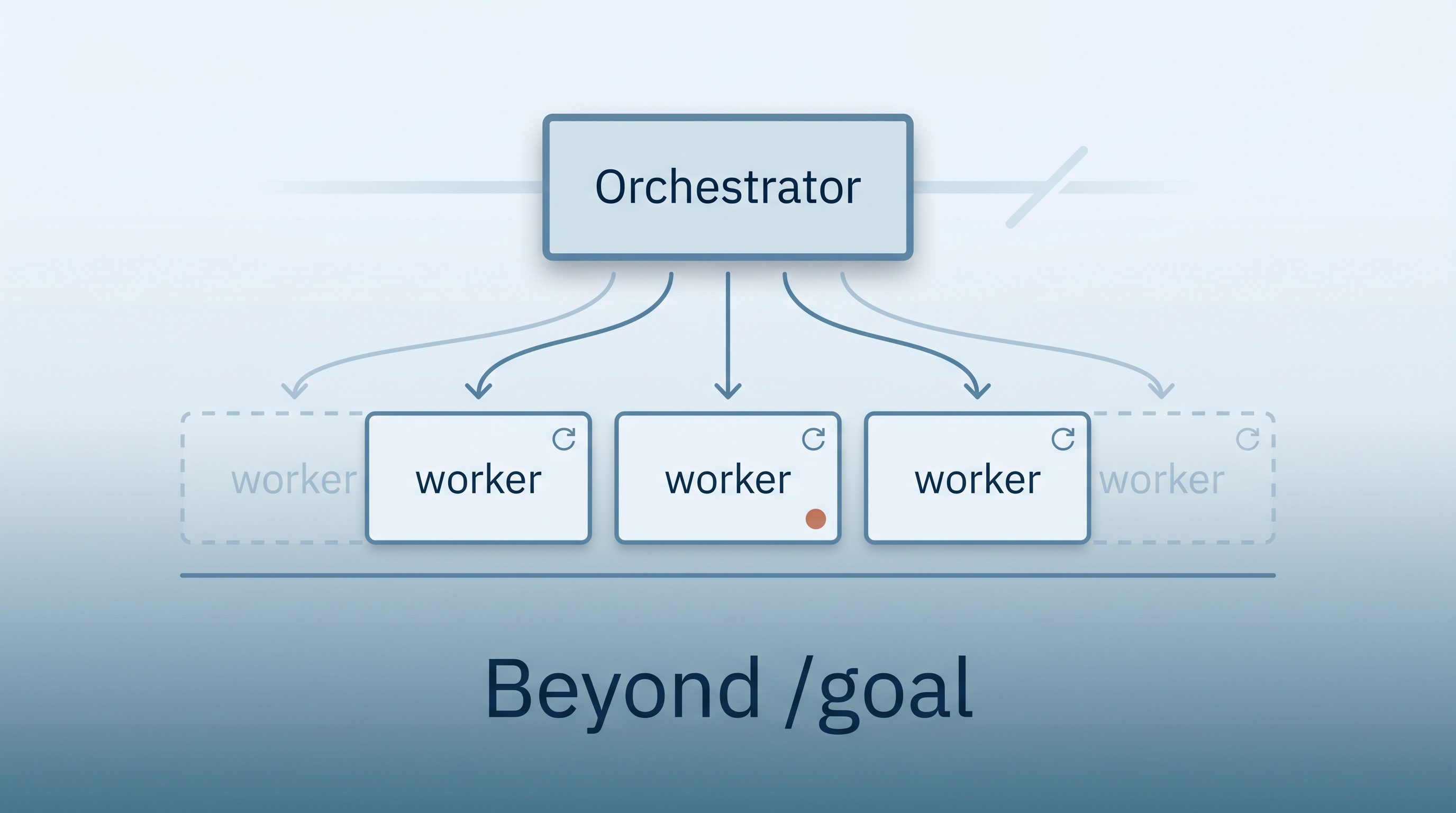
Anthropic shipped /goal in Claude Code 2.1.139 (May 11, 2026 per official changelog; widely covered May 12): you state a completion condition, and the agent keeps working across turns until a separate fast model (Haiku by default) reads the transcript so far and decides whether the goal is met. It’s the closest Claude Code has come to a “set it and walk away” mode. But the agent’s iterations all share one conversation context window — and once that window fills, accuracy collapses, the agent can hallucinate, and the transcript evaluator (which itself only sees the same transcript) can plausibly mark the goal complete when it isn’t. This entry teaches what /goal does, why it isn’t sufficient for hour-scale or day-scale runs, and the Orchestrator + Headless pattern (popularized in a May 15, 2026 walkthrough by Eric Tech) that puts the autonomy where the context wall can’t reach it.
What /goal is, in one minute
You type /goal inside Claude Code’s terminal and provide a completion condition, e.g.:
/goal Migrate all legacy Auth components to the new design system,
and ensure tests pass.
Claude then:
- Plans how to satisfy the condition
- Executes edits, tool calls, test runs
- Evaluates whether the condition is met — a separate fast model (Haiku by default) reads the transcript so far and votes “done” or “keep going.” It does not run tools, inspect files, or verify the repo state; it only judges the conversation it can see.
- Loops — if not met, planning starts again
It tracks elapsed time, turns, and tokens; when the evaluator agrees the goal is satisfied, the goal clears and you get your terminal back. Available in interactive mode, programmatic mode (-p), and Remote Control.
The fundamental problem — the context wall
“The slash-goal here typically stays in the same active conversation context window — meaning it will absolutely hit the context wall as the conversation progresses.” — Eric Tech
Each plan → execute → evaluate cycle of /goal adds to the same context window. The longer the run, the more the LLM’s effective accuracy drops. At some point — and you can’t predict exactly when — the agent:
- Mis-plans a step because earlier decisions have drifted out of focused attention
- Hallucinates a tool output or a file’s contents
- Worst case: during the evaluation step, hallucinates that the condition is met when it isn’t
This is the failure mode /goal cannot solve from inside its own conversation: the system that’s about to make a critical “are we done?” decision is precisely the system whose attention is being eroded.
┌─ One growing context window ─────────────────────────────┐
│ │
│ plan ─▶ execute ─▶ evaluate ─▶ plan ─▶ execute ─▶ ... │
│ │
│ ◀─── context fills, accuracy drops ───▶ │
│ │
│ ⚠ false "condition met" possible near the wall │
└──────────────────────────────────────────────────────────┘
The pattern: Orchestrator + Headless
The fix is mundane: stop doing the work inside the orchestrator’s own context window. Split the system into two roles:
┌─────────────────────────┐
│ Orchestrator session │ ← stays small, low context %
│ (single Claude Code │ ← decides "what's next"
│ conversation; you │ ← reads state; dispatches
│ keep this clean) │
└────────────┬────────────┘
│ for each iteration:
▼
┌─────────────────────────┐
│ Headless worker │ ← fresh context each time
│ (claude -p ...) │ ← does the real work
│ │ ← can spawn its OWN subagents
│ Reports terse result. │ ← *terminates* when done
└─────────────────────────┘
│
▼
state file / GitHub project
(the actual memory)
Why this works:
- The orchestrator only sees terse iteration results — small, structured handoffs (e.g., “QA found 3 bugs; bug IDs in GitHub project”). Its context stays well below the wall.
- Each headless worker is born with a clean context, does its iteration, writes state externally, and dies. There’s no accumulating drift across iterations.
- The “memory of the project” lives in a state file or GitHub project, not in any LLM’s conversation.
Why not just use subagents? A subagent reports its findings back to the parent — that means everything it produced ends up consumed in the parent’s context. Eric’s argument: for hour- or day-scale autonomous work, you want the orchestrator to stay so clean that subagents are a luxury it can’t afford. The headless worker can spawn its own subagents without polluting the orchestrator.
State: where the project actually lives
Eric’s recommended substrate: GitHub Projects columns. Anything else works — a .md file, a SQLite DB — but GitHub Projects has two practical wins:
| Why GitHub Projects | Detail |
|---|---|
| Free | No new infrastructure |
gh CLI built into Claude Code |
The agent can read/write tickets without an MCP server |
| Visible to humans | You can watch the run unfold in a browser, intervene, re-prioritize |
| Per-ticket history | Each ticket carries its own audit trail |
Eric uses six columns:
| Column | Meaning |
|---|---|
| queue | Items pending — the orchestrator pops from here |
| testing | Item currently in flight |
| done | Spec passing |
| bug | Test failed; needs the build worker |
| flaky | Only works on retry |
| skip | Out of scope |
The orchestrator’s job each iteration is essentially: “pop one from queue, dispatch the right headless skill, move the result to the right column.” That’s it. The interesting work is in the skills.
Worked example: Super-QA + Super-Build cycling on an app
Eric’s walkthrough demonstrates the pattern with two headless skills orchestrated by a third super-orchestrator skill:
super-orchestrator ─▶ super-QA ─▶ finds bugs ─▶ GitHub bug column
▲ │
│ ▼
└─◀── super-build ◀── fixes bugs ◀── GitHub bug column
super-QA (find bugs)
- Traverses the app’s pages using breadth-first search
- Visited set keeps it from re-testing pages it already covered
- Writes Playwright end-to-end tests for each page
- If a test fails → opens a ticket in the bug column
- If a page has child pages → adds them to queue
- Terminates the headless session, returns “found N bugs”
super-build (fix bugs)
- Reads from the bug column
- Uses the Superpowers TDD framework (obra/superpowers): write failing test → implement → refactor → verify
- For non-obvious design decisions, invokes Gstack — Garry Tan’s auto-decision skill. (Note: Eric describes
/autoplanas voting across CEO / engineer / security / designer / QA roles; the upstream Gstack/autoplanactually runs a CEO → Design → Eng → DX chain with six auto-decision principles and dual Claude/Codex voices. Treat Eric’s framing as a useful mental model, but read the actual Gstack source before adopting.) - Terminates with “fixed M bugs”
The loop terminates when
There are no items left in queue AND no items left in bug. That’s the completion condition the orchestrator monitors — external to any single LLM conversation.
Why this is “Agentic Engineering” rather than “prompt engineering”
The Orchestrator + Headless pattern is a small case study in the Agentic Engineering primer’s five-layer framing:
| Layer | What this pattern does |
|---|---|
| Prompt | Iteration prompts are short and structured (“here’s ticket #N, do super-QA on it”) |
| Agent | Two roles — orchestrator (long-lived, clean) + worker (short-lived, fresh). Memory lives in state, not context. |
| LLM | Same model; the win is how it’s invoked, not which model |
| MCP | Tools are normal — gh CLI, Playwright, file edits |
| Tools | Workers spawn freely; no parent-context pollution |
The diagnostic question shifts from “is my prompt good?” to “is my orchestrator’s context window staying small?”
Teaching Mode — for CS-310 students
A two-week classroom unit, paired with the What is Agentic Engineering? primer. Plan for heavy scaffolding — Claude Code setup, account/auth/token caps, a pre-wired GitHub project, and a mock target repo should all be provided. Six contact hours is tight if students are configuring Claude Code from scratch; the lab times below assume the starter materials are ready on Day 1.
Week 1 — /goal in isolation (~2 hr lab)
| Activity | Output |
|---|---|
| Read this entry; watch the Eric Tech video | Students can articulate the context-wall problem in their own words |
In pairs, run a short /goal task on a provided sample repo and observe the context-usage indicator as it runs |
A note describing what they saw — typically a steady climb in context % as iterations stack up |
Week 2 — Refactor into Orchestrator + Headless (~4 hr lab)
| Activity | Output |
|---|---|
Provided starter: an orchestrator skill that calls claude -p for each iteration, plus a pre-configured GitHub project with the six columns and 5-10 seed tickets |
Students wire up a single iteration end-to-end |
| Replace the in-context loop from Week 1 with the orchestrator pattern; re-run on the same sample repo | The same task, now with a flatter orchestrator context line because the work happens in fresh claude -p sessions |
1-page reflection: when is plain /goal actually fine? |
Forces the student to name the threshold (short, single-pass, low-stakes tasks) — not every problem needs the orchestrator pattern |
Assessment
- Practical: provide a buggy app + a target spec; the student must build an orchestrator that drives it to green
- Conceptual: given a transcript with a “false complete,” identify which iteration drifted and why the context-wall caused it
How LearnAI Team Could Use This
- Production-style autonomous-agent demonstrations — the orchestrator + headless pattern is a useful way to show “AI building software overnight” without students drawing the wrong lesson (that
/goalalone is sufficient). - Onboarding senior students to long-running agent workflows — the orchestrator-vs-worker split is a common abstraction in modern AI-engineering practice and worth surfacing before students hit it in industry.
- Security teaching (CS-336) — the false-completion failure mode has a security flavor: an evaluator that only reads the transcript can be misled if the transcript itself has been corrupted by context drift (intentional or not). Worth at least a 1-hour discussion.
- Companion to existing entries — pair with Gstack (decision-voting), Harness Engineering (why the runtime layer matters), and Autoresearch (an earlier autonomous-loop pattern).
Real-World Use Cases
| Scenario | How to use the pattern |
|---|---|
| Overnight bug-fix sweep on a legacy module | Orchestrator + super-QA + super-build; goal: “queue is empty AND bug column is empty” |
| Migrating a UI component library | Orchestrator drives one component per iteration; state in GitHub project; each iteration handled headlessly |
| Mass API documentation backfill | Orchestrator iterates over endpoints from a state file; worker writes + verifies docs per endpoint |
| Long-form research synthesis | Orchestrator iterates over a reading-list state file; worker reads + summarizes one paper at a time |
| Course-grading automation (LearnAI use case) | Orchestrator iterates over student submissions; worker runs the rubric + writes a feedback artifact per student |
Important things to know
/goalalone is fine for short, single-pass tasks. The point isn’t that/goalis broken — it’s that the context-wall failure mode is invisible until it bites you. Use/goalfor short, bounded jobs where the entire run fits comfortably inside a fresh context window; reach for the orchestrator pattern when the task plausibly runs hour-scale or longer.- The evaluator is not a safety net. Anthropic’s Haiku evaluator helps, but it reads the transcript only — no tool calls, no file inspection. Don’t trust “condition met” as ground truth on long runs; check the actual repo state.
- Subagents are not a substitute. Subagent results flow back into the parent’s context, defeating the point. The headless
claude -pinvocation is what keeps the orchestrator clean. - State must live outside any LLM conversation. A
.mdfile, a SQLite DB, or GitHub Projects — pick one and commit. The orchestrator should be able to crash and restart without losing progress. - Cost is real. Hour- and day-scale runs incur hour- and day-scale token bills. Set hard limits at the orchestrator layer (max iterations, max tokens), not inside
/goal. - The orchestrator skill is where most of the engineering effort lands. Queue management, retry policy, the “is this iteration good enough to commit?” check, escalation to humans when stuck — all of these live here, not in the worker skills.
- Companion deep-dives in this wiki:
- What is Agentic Engineering? A Teaching Primer — the 5-layer framework that contextualizes this pattern
- Harness Engineering — The Real Bottleneck Isn’t the Model — orchestrator design as a discipline
- Claude Code · CLAUDE.md Practices — how to manage what does live in context
- Agents Need Control Flow — argument for code over prompts in the orchestrator layer
- Gstack — Garry Tan’s AI Software Factory — the decision-voting layer Eric’s super-build uses
- Autoresearch — Autonomous ML Experiments Overnight — an earlier instance of the same idea, applied to ML training loops