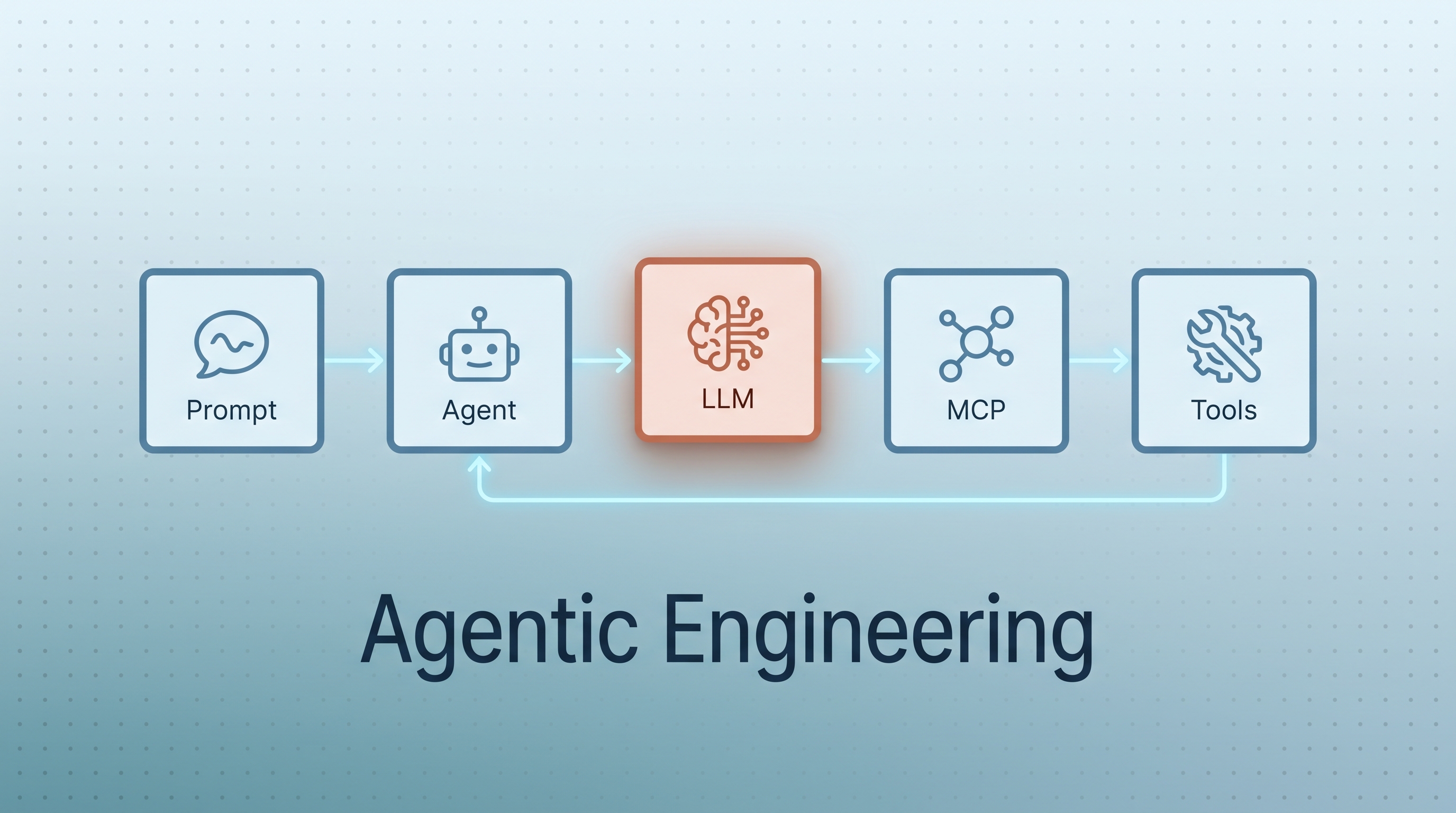
Agentic engineering is an emerging applied subarea at the intersection of software engineering, AI/ML engineering, and reliability practice for LLM-mediated systems — software systems where a large language model is one component of a larger goal-directed loop with planning, memory, tool use, and verification. The discipline organizes around five interacting layers — Prompt (提示词) · Agent (智能体) · LLM (大模型) · MCP · Tools (工具) — and the question every practitioner keeps asking is: “when something fails, which layer is responsible?” This entry is a teaching primer for faculty preparing CS-310 / CS-336 / AI-literacy lectures: it defines the discipline, names the five components, and lays out a 4-week course module.
| *Companion entry — same 5-component framework with a vocabulary lens: AI Agent Primer — The Vocabulary Ladder and 18-Step Workflow | Live interactive animation (lecture-ready, single page): agentic-engineering-flow* |
This entry is the “engineering” lens. Vocabulary definitions live in the companion primer above. This entry assumes the vocabulary and asks the next question: how do you actually engineer, instrument, and debug one of these systems?
Why “Agentic Engineering” deserves a separate name
Three older labels almost cover the work, but each was scoped before LLM-mediated systems became routine:
| Older label | Where it overlaps | Where agentic engineering pushes further |
|---|---|---|
| Prompt engineering | Crafting the instruction sent to the LLM | Adds planning, memory, tool selection, recovery — across many model calls per task |
| Software engineering | Code, testing, deployment, observability | Adds first-class handling of non-deterministic model behavior inside the system |
| ML engineering / MLOps | Training, serving, evaluation, monitoring | Treats the trained model as fixed and engineers the runtime orchestration around it |
Agentic engineering sits where all three meet: you accept the LLM as a fixed-but-stochastic component and engineer the surrounding system — prompts, planning, memory, tool selection, verification, error recovery — so the whole thing behaves reliably enough to ship.
The five-component framework (one-page reference)
A compact decomposition used widely in popular Chinese-language AI explainers and consistent with how production agent stacks (Claude Code, Codex, LangChain, LlamaIndex) actually organize their code. The five components, English-first with the original Chinese terms preserved:
| # | Component | One-line role | Key engineering question |
|---|---|---|---|
| ① | Prompt (提示词) | The instruction layer — role, task framing, output shape | Are your prompts versioned, reproducible, and traceable to behavior changes? |
| ② | Agent (智能体) | Decision/dispatch layer — planning, memory, tool selection, verification | Is the plan inspectable? When the agent picks the wrong tool, can you tell why? |
| ③ | LLM (大模型) | Cognition layer — reasoning, classification, generation | When you swap the LLM (Claude → GPT, etc.), what breaks that shouldn’t be model-specific? |
| ④ | MCP | Connection layer — a protocol boundary between agent/runtime and external tools/data | Are tool boundaries explicit and least-privilege, or did you grant broad access “just to get it working”? |
| ⑤ | Tools (工具) | Action layer — web search, code execution, DB query, API calls | When a tool call fails, does the agent recover, retry intelligently, or hand the raw error to the user? |
One-line summary, paraphrased from the popular explainer this framework comes from: Prompts spark intent; the LLM provides cognition; the Agent decides and dispatches; MCP standardizes the connection; tools execute in reality — the five together form the loop that lets AI both think and act.
For per-component definitions, examples, and deeper history, see the Vocabulary Primer. The rest of this entry assumes the words and pivots to engineering practice.
A more accurate picture of MCP than most explainers give
The compact framework above flattens MCP to a single “protocol layer” — useful for teaching, but worth refining once students are past the first lesson. Official MCP architecture has three roles (host / client / server) communicating over JSON-RPC; servers expose tools, resources, and prompts, and clients discover and invoke them. A few caveats most explainers skip:
- MCP makes exposed operations explicit, but it does not by itself guarantee least privilege — official Anthropic docs recommend human-in-the-loop approval and warn that tool annotations are untrusted. Treat MCP as a transport / discovery convention, not a sandbox.
- “Any MCP-compatible agent can use any MCP-compatible tool” is aspirational, not absolute. Compatibility depends on protocol version, transport, auth, declared capabilities, schemas, and permissions. Production deployments still bind specific clients to specific servers.
- Other ecosystems achieve the same role differently — OpenAI’s function calling, custom RPC, LangChain tool interfaces. The layer is universal; MCP is one (currently dominant in the Anthropic/Claude orbit) implementation.
Layer-attribution — the diagnostic question
Once students have the framework, the highest-leverage skill is layer-attribution: when something goes wrong, name which layer (or layer boundary) is responsible. A worked diagnostic table:
| Observed symptom | Likely failing layer(s) | What to check |
|---|---|---|
| Agent confidently asserts false facts | LLM + Prompt | Did the prompt require grounding via a tool? Did the agent skip the search step? |
| Agent picked the wrong tool | Agent / LLM / tool-schema boundary | Inspect the plan; check the tool descriptions / schemas the LLM was given |
| Tool returned an error and agent ignored it | Agent runtime (no retry / verification path) | Is there a fallback? Does the agent observe the tool’s return? |
| Same tool call hangs forever | Agent runtime (timeout enforcement) + MCP / Tool | Did the agent set/enforce a timeout? Is the MCP server healthy? |
| Agent forgets earlier turns | Agent memory / context management | Is the context window full? Is memory written/read deliberately or by accident? |
| Cost is 10× what you expected | Agent runtime (loops/retries) + Prompt + LLM routing | Look for retry loops, full-context memory injection, retrieval over-fetching, and unnecessary high-tier model calls |
| Two students get totally different outputs from the same prompt | LLM non-determinism | Set temperature; cache prompts; check for randomized tool ordering |
This table is the centerpiece of an “Agentic Engineering 101” lab — students reproduce each symptom, diagnose the layer, fix it, and write up what they learned.
Teaching Mode — A 4-Week Module for CS-310
This is the bit that makes this entry different from a vocabulary glossary: a concrete syllabus block you can paste into an existing course. Aimed at upper-level undergrads who can program but haven’t worked with LLMs. Plan for 6-10 instructor hours of prep the first time you teach it, and budget provide-a-starter-repo for Weeks 2-4 so students aren’t building MCP servers from scratch.
Week 1 — Vocabulary + first agent demo (1-2 hr)
| Activity | Output |
|---|---|
| Read this entry + the Vocabulary Primer | Students can name the five layers and one example tool each |
| Watch one agent run live (Claude Code on a small repo) and pause at every layer transition | Class-produced annotated transcript marking each layer crossing |
Week 2 — Build a minimal agent (~4 hr lab; provide a starter repo)
| Activity | Output |
|---|---|
| Using a provided starter (Python; OpenAI/Anthropic SDK + a mock “web-search” tool so students aren’t fighting API keys) implement: (a) prompt, (b) LLM call, (c) one tool call, (d) one synthesis step | A working ~100-line minimal agent that exercises layers ①②③⑤ |
| Annotate which lines implement which of the five layers | Annotated diagram of student’s own code |
(MCP is optional in Week 2 — the starter exposes the tool through a simple Python interface. Students who want to plug into a real MCP server can do that as extension work.)
Week 3 — Instrument it (debugging) (~3 hr lab + 1 hr lecture)
| Activity | Output |
|---|---|
| Add logging to every layer crossing the student’s code actually has (typically: prompt → LLM, LLM → tool, tool → result, result → LLM-synthesize) | Students see their agent’s internal trace, not just its final output |
| Reproduce three failure modes from the diagnostic table; diagnose each | Three short writeups: symptom → suspected layer → evidence → fix |
Week 4 — Harden it (~3 hr lab)
| Activity | Output |
|---|---|
| Add: retry on tool failure, agent-side timeout/cancellation, verification step before returning to user, cost cap on LLM calls | An agent that survives realistic real-world conditions |
| Final reflection: which engineering discipline does this remind you of most — distributed systems? embedded? front-end? | A 1-page essay placing agentic engineering in the existing engineering landscape |
Assessment ideas
- Pop quiz (10 min): given a transcript of an agent run, mark which step belongs to which layer
- Lab grading rubric: did the student instrument every layer crossing their code actually has? Can they explain why a specific log line implies a specific layer is at fault?
- Term project: pick a domain (academic-paper search, code review, …) and engineer an agent for it. Submit: the agent, the trace logs of three different queries, and a layer-by-layer reflection.
How LearnAI Team Could Use This
- Primary fit: CS-310 (Advanced OO Design) — the 4-week module slots into CS-310 cleanly as a system-design case study. The five components map to “separation of concerns” patterns students already know.
- CS-336 (Program Analysis for Security) only with a security framing. This module fits CS-336 if you frame the lab around agent-and-tool security: prompt injection, taint / information-flow through tool boundaries, tool sandboxing, MCP permission models, and what happens when an LLM is convinced to misuse a tool. Don’t drop the generic version into CS-336 — re-shape it around security first.
- Faculty-development workshop — run the 4-week module in compressed form (one 3-hour workshop) for colleagues who want to understand what their students are now using.
- Diagnostic framework for student help requests — when a student says “my AI thing isn’t working,” use the diagnostic table as the triage flow before going deeper. Cuts office hours significantly.
- Cross-discipline outreach — the five-component framework is language-light enough that non-CS faculty (bio, finance, design) can use it to explain why their colleagues are hiring agents instead of interns.
Real-World Use Cases
| Scenario | Description |
|---|---|
| Onboarding new engineers | First reading before they touch the production agent stack — establishes shared vocabulary |
| Failure-mode review | When a deployed agent misbehaves, classify the failure by layer before assigning a fix owner |
| Tool evaluation | When a new “agent platform” launches, decompose its pitch into the five layers — what’s actually novel vs. rebranded |
| Vendor selection | When deciding between LangChain vs. Claude Code vs. an in-house stack, evaluate per-layer support |
| Curriculum design | Use the 5-layer × 4-week module as the agentic-systems unit in an upper-level CS course |
| Stakeholder briefing | When asked “what is an agent?” by a dean or industry partner, the framework covers most of the answer in 10 minutes |
Important things to know
- The five-component framework is a teaching artifact, not a formal architecture. Real agent frameworks (LangChain, LlamaIndex, Claude Code, Codex) implement these roles differently and sometimes collapse layers — Claude Code, for instance, blurs Agent and LLM behavior in places. The five components are a mental map useful for teaching and diagnosis; treat any production system as your authoritative source.
- The Agent runtime carries more responsibility than most diagrams suggest. When you see “Tool hung” or “cost 10×,” the failure is often at the agent runtime / orchestrator layer (timeouts, retry loops, context management), not at the Tool or LLM. Teach the runtime as a first-class layer.
- “MCP” is one specific protocol (Anthropic’s Model Context Protocol). Other agent ecosystems use other connection layers. The role it plays — standardized agent/tool bus — exists in every system; the implementation varies.
- Skills are not one of the five components — they’re a popular implementation pattern within the Prompt + Agent layers (small, file-based, agent-loadable procedures). Treat Skills as a companion concept, not a sixth layer.
- Companion deep-dives in this wiki:
- AI Agent Primer — Vocabulary Ladder and 18-Step Workflow — the vocabulary counterpart to this engineering primer
- Harness Engineering — The Real Bottleneck Isn’t the Model — the agent-runtime / orchestrator layer in depth
- Agents Need Control Flow — argument that the Agent layer should be code, not just LLM-prompted decisions
- Agentic AI Engineer Roadmap 2026 — Eight Pillars — career-development view on the same discipline
- How Anthropic Uses Skills — Thariq’s Framework — Skills as a Prompt-layer implementation pattern
- grill-me — When AI Interviews You Before Writing Code — a Prompt-layer pattern that improves Agent-layer planning